UTF-8の4バイト文字「土の異体字」を処理してくれない
2018年 04月 08日
今回は突然だが、文字コードの話をする。
というのは、ちょっとPythonでAI日本語処理らしきことをやっていたら、引っかかってしまったからである。
というのは、ちょっとPythonでAI日本語処理らしきことをやっていたら、引っかかってしまったからである。
図に、3つの土を、そのUTF-8のコードと共に示す。
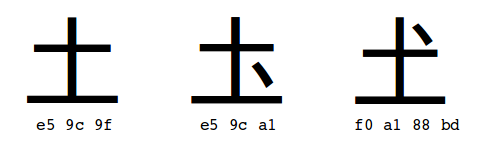 引っかかった文字は土の異体字の一つの下図の右端の字である。
引っかかった文字は土の異体字の一つの下図の右端の字である。
引っかかった文字は土の異体字の一つの下図の右端の字である。今では多くのソフトがUTF-8を標準として採用し、たとえ英語圏で開発されたソフトでも日本語処理に困らないことが多い。
しかし、それは、3バイトの漢字までで、4バイトになってしまう「土の異体字 」は扱えないことに出くわすことが多い。
しかし、それは、3バイトの漢字までで、4バイトになってしまう「土の異体字 」は扱えないことに出くわすことが多い。
最近、世のブームに引きずられてという訳ではないのだが、AI、言語処理系の何かをするとき、Pythonはツールが揃っているので使うことが多い。
Python自体は、4バイトの漢字も扱えるのだが、Pythonに非常にたくさんあるパッケージの中には扱えないものもある。
Pythonで文字処理をしていたのだが、GUIを用意しないと不便だなと思い、PythonのGUIツールキットのTkinterを使って簡単なGUIを作りつつあるところだ。
それで、用意してあるテキストファイルを処理しようとしたら、「土屋(異体字)」さんの情報を処理しようとしたところで止まってしまった。
実際には、長いテキストをTextウィジェットに貼り付けるメソッドを呼び出しただけなのだが、エラーが出てしまった。
直接Textウィジェットに、「????」を挿入したらとりあえず文字は表示されたのだが、その後テキストを編集してみたら、消去やカーソル移動が発狂してしまった。
要するに、UTF-8の4バイトコードに対応できていない。
地名、人名などを扱う、つまり事務処理、文字情報の整理などをしようとすると、UTF-8の4バイト文字に必ず遭遇してしまう。
UTF-8は、4バイトどころか、6バイト文字までサポートしているので、完全サポートというなら、そこまでちゃんとやらないとダメなのだが、ASCII文字だけで暮らしているエンジニアが多国語対応すると、こういうことになっているので、気をつける必要がある。
このあたり、東アジアの漢字圏のエンジニアが対処しないときちんとしたものにならないようだ。
昔は、データベースの対応もボロボロだったが、今は良くなっているのかな。

#人気の記事
#タグ


