MPI対応にするには、いつものように以下のオマジナイを最初に行う。
from mpi4py import MPI
comm = MPI.COMM_WORLD
rank = comm.Get_rank()
size = comm.Get_size()都市の位置決め
MPIでは、複数のノードで都市の位置データを持つことになるのだが、すべてのノードで位置が同じでないと無意味である。さらに、走らせる度に都市の位置が異なってしまうと、比較に使えない。
そのため、マスター(rank 0)で、乱数の初期値を固定して都市の位置を決めるようにし、決まった位置をその他のノードにブロードキャストした。
class TSP():
def __init__( self, cnt, sz, scl, gen, g_gap, x_gap ):
global ga, org_points, path_length, pool_size
self.count = cnt
self.scale = scl
if rank==0:
self.make_new_points()
org_points = self.points
org_points = comm.bcast(org_points, root=0) ## MPI 点のBroadcast
path_length = len(org_points)
pool_size = sz
ga = GA()
ga.initializePool()
random.seed() ## random seed
ga.stepForward(gen,g_gap,x_gap),
個体交換(島モデル)
進化の間で、一定の世代間隔で、各ノードから1個体を選んで、次のノードに転送する。
この個体の転送のことを移民とも言う。
def stepForward( self, n, pgap, xgap ):
# n=世代数、pgap=印字世代間隔、xgap=交換世代間隔
global generation, pool, x_gen, y_len
generation = 0
self.printInfo() # 0世代のプリント
self.snap_gap = pgap
self.exchange_gap = xgap
for generation in range(1,n+1): # 第n世代までループする
self.oneGeneration() # 1世代だけ進める
self.best_individual = pool[0]
## グラフ表示のために、全ランクの最短距離を集める
if generation % 10 == 0:
len_all = comm.gather(self.getMinLength(),root=0)
if rank == 0:
x_gen.append(generation)
for i in range(size):
y_len[i].append(len_all[i])
if generation % self.snap_gap == 0: # 指定の世代間隔で
self.printInfo() # 個体プールの情報をプリント
## MPI 島モデル:最良の個体を交換する
if generation % self.exchange_gap == 0:
# poolの先頭個体を次のrankへ送る
rank_to = (rank+1) % size
comm.isend(pool[0], dest=rank_to, tag=1)
# 受け取った個体を、poolの先頭に入れる
pool[0] = comm.recv(source=MPI.ANY_SOURCE, tag=1)
if generation % self.snap_gap != 0:
self.printInfo()各プログラムのノードはrankで与えられる。このrankでの最良個体を、次のノードに送ることを考える。そのために、(rank+1) % size で転送先のノードを決める。
comm.isend()にて、とにかく個体を送りつけてしまう。この関数は、送り終えることを確認することなく直ぐに戻ってくる。
次に、送られて来ているはずの個体は隣のノードでの最良個体のはずだから、自分のpoolの最良個体があったところ pool[0] に突っ込む。
ノードのことを、この方法では島と呼び、この交換を一定世代毎に繰り返し行うと、ノード全体であたかも複数ノードが連携しながら進化が進むことになる(といいな)。
この方法を島モデルと呼ぶ。
各ノードの進化状況
複数のノードで、ほぼ別々に進化するようにしたのだが、そのとき、各ノードでどのように進化が進んでいるのかの状況を把握したい。
そのために、一定の世代間隔(ここでは10世代間隔)で、それぞれのノードの最短距離をマスター(rank==0)に集めている。
リストx_genが世代数リストで, y_lenは2次元のリストで、y_len[ランク]に、各ランクにおけるx_genに対応したところに、その世代の最短距離を入れている。つまり、y_lenは2次元のリストである。
comm.gather()により、現時点の各ノードの最短距離を集めて、y_lenにノード別にappendしているだけである。
すべての進化が終了し、最後に進化の様子をグラフで示している。上記のように、x_gen, y_lenのリストが用意できていれば、各ノードの最短距離の変化をグラフで示すのは、plt.plotに、世代と最短距離の対応したリストをわたすだけで済む。各ノード別に自動的に色が付けられる。
if rank==0:
## 進化グラフ
for i in range(size):
plt.plot(x_gen, y_len[i])
plt.show()実行
Raspberry Pi 1台にノードずつ8台で8ノードのMPIを動かすために、hostfileを用意した。
rp0 slots=1
rp1 slots=1
rp2 slots=1
rp3 slots=1
rp4 slots=1
rp5 slots=1
rp6 slots=1
rp7 slots=1MPI対応版のPythonファイル名は、TSP_Twist_MPI.plyにした。
引数を指定せずに実行すると、引数の形式を示す。
pi@RP0:/beta/TSP/Twist $ mpiexec -hostfile host1x8 python3 TSP_Twist_MPI.py
usage: python3 TSP_Twist_MPI.py 都市数 個体数 世代数 表示間隔 交換間隔都市数:100, 個体数:100, 世代数:1000, 表示間隔:100, 交換間隔:10 の設定で実行した。
pi@RP0:/beta/TSP/Twist $ mpiexec -hostfile host1x8 python3 TSP_Twist_MPI.py 100 100 1000 100 10
R:4 G:0 len=19847.894 ave=22003.298
R:3 G:0 len=20020.734 ave=21945.181
R:6 G:0 len=20123.220 ave=22072.970
R:5 G:0 len=19380.752 ave=21930.215
R:1 G:0 len=19628.057 ave=21876.876
R:7 G:0 len=19456.725 ave=22079.189
R:2 G:0 len=19311.690 ave=21919.987
R:0 G:0 len=20041.209 ave=22113.650
中略
R:7 G:1000 len=4116.517 ave=4159.534
R:5 G:1000 len=4116.517 ave=4162.903
R:6 G:1000 len=4116.517 ave=4162.407
R:4 G:1000 len=4118.698 ave=4169.964
R:3 G:1000 len=4089.444 ave=4162.547
R:2 G:1000 len=4095.830 ave=4156.980
R:1 G:1000 len=4106.785 ave=4167.835
R:0 G:1000 len=4087.624 ave=4164.437
Time 21.811217 sec
RSS 64.029 MB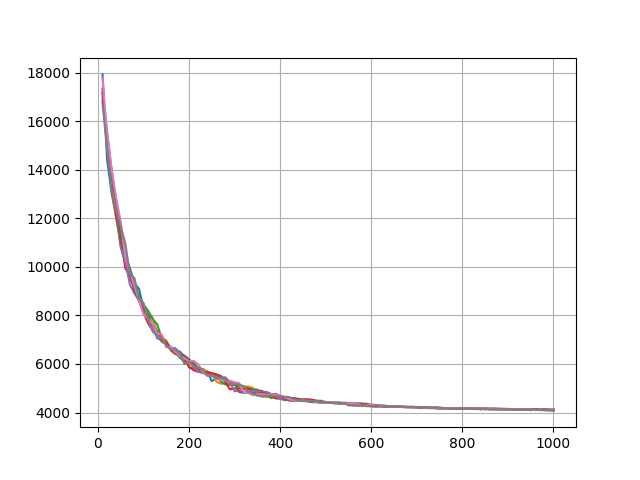
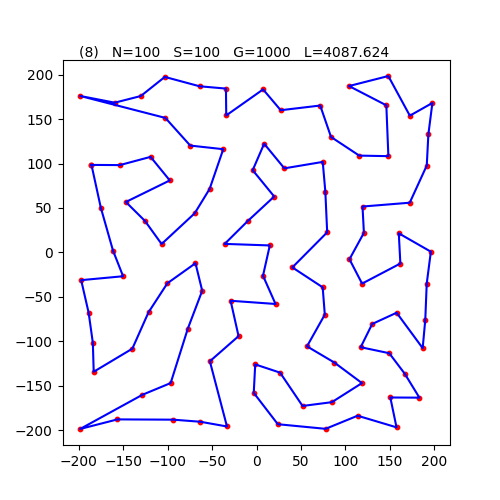
単独で100都市、100個体、1000世代で実行したときには、最短距離は4234〜4429の間に分布していたのだが、MPIで繋いだことにより、さらにより良い最短距離 4087の巡回路が得られた。
もう巡回路の交叉はなくなっているが、まだ何となく不十分な気がする。
単独で100都市、100個体、1000世代での実行時間は約20.9秒だった。MPIで並列処理にしたらわずかに遅くなり21.8秒となった。MPIによる個体移動などのオーバーヘッドに若干の時間がかかっているようだが、せいぜい5%程度の遅れに過ぎない。それよりも、最短距離が確実に短くなったので、MPIを利用すべきである。
ついでに、MPIで10000世代まで実行してみた。
pi@RP0:/beta/TSP/Twist $ mpiexec -hostfile host1x8 python3 TSP_Twist_MPI.py 100 100 10000 100 10
R:4 G:0 len=19742.219 ave=22017.995
R:1 G:0 len=18606.409 ave=21972.709
R:5 G:0 len=19874.469 ave=21873.883
R:6 G:0 len=19675.823 ave=21984.702
R:7 G:0 len=19864.333 ave=22099.491
R:2 G:0 len=19506.143 ave=21923.188
R:3 G:0 len=20116.192 ave=21950.991
R:0 G:0 len=20041.209 ave=22113.650
R:5 G:100 len=8709.272 ave=8993.365
R:4 G:100 len=8717.987 ave=8901.163
R:3 G:100 len=8488.176 ave=8682.230
R:2 G:100 len=8408.409 ave=8661.284
R:1 G:100 len=8435.267 ave=8731.664
R:7 G:100 len=8634.270 ave=8787.667
R:6 G:100 len=8618.970 ave=8977.578
R:0 G:100 len=8094.063 ave=8641.352
中略
R:7 G:10000 len=3898.092 ave=3910.350
R:6 G:10000 len=3898.092 ave=3909.441
R:5 G:10000 len=3898.092 ave=3909.978
R:4 G:10000 len=3898.092 ave=3910.185
R:3 G:10000 len=3898.092 ave=3909.734
R:2 G:10000 len=3898.092 ave=3910.378
R:1 G:10000 len=3898.092 ave=3910.233
R:0 G:10000 len=3898.092 ave=3910.231
Time 231.221094 sec
RSS 64.651 MB単独で100都市、100個体、10000世代で実行したときには、最短距離は3947〜4015の間に分布していたのだが、MPIで繋いだことで、より良い最短距離 3898の巡回路が得られた。

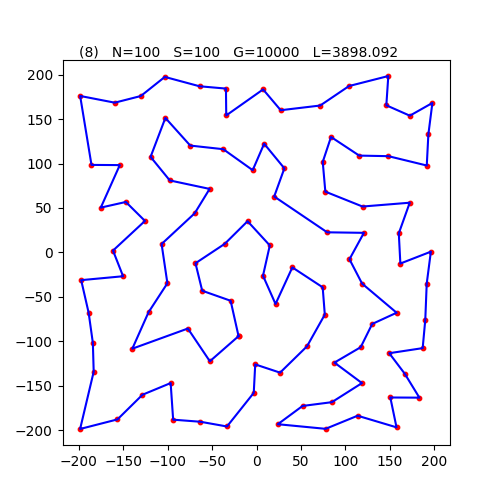
世代数、個体数を増加させれば、もっと短い巡回路が見つかりそうである。
比較
MPIを使って8ノードにした場合の進化の様子を調べたが、MPIを使わない場合との比較をして、MPIの有効性を調べよう。
MPIを用いない場合に、100都市、800個体、10000世代とした場合、つまり8ノードにする代わりに個体数を8倍の800個体にした場合との比較をしておこう。今回も、8回走らせて重ねて描いてみた。
$ mpiexec -n 8 python3 TSP_Twist_MPI.py 100 800 10000 100 100000
中略
R:7 G:10000 len=3866.791 ave=3886.661
R:5 G:10000 len=3850.337 ave=3877.124
R:1 G:10000 len=3841.297 ave=3865.938
R:4 G:10000 len=3859.931 ave=3883.082
R:6 G:10000 len=3870.254 ave=3894.601
R:0 G:10000 len=3973.560 ave=3991.797
R:3 G:10000 len=3897.881 ave=3918.219
R:2 G:10000 len=3851.923 ave=3871.142
Time 1308.900721 sec
RSS 73.892 MB実際に8回走らせるのは面倒だし、ましてそれをRaspberry Pi で行うと時間がかかってしまうので、AMD/Threadripper上で行った。
TSP_Twist_MPI.pyを使って、MPIを使ってはいるのだが、世代交換間隔を100000世代毎に指定しているので、実際には個体交換は行われていない。
個体数800にして8回走らせた結果は、最短距離が3841~3897となり、MPIで個体数100、ノード数8の場合の結果よりも良くなっている。しかし、実行時間は大差がついている。個体数800の場合1308秒かかっていたのが、個体数100で8ノードの場合49になっており、時間が1/26になっている。個体数が増加すると、急激に実行時間が長くなっていくので、個体数を増やすより、ノード数を増やした方が良さそう。
天変地異
遺伝的アルゴリズムで進化をさせていても、進化が全然進まなくなることがよくある。本当の最適解になっているのなら良いのだが、ほとんどの場合は局所最適解に陥っている。
生命の進化を考えると、進化が停滞してしまうことはあっただろうと思われる。地球上では、時々、多くの生命が失われる位の天変地異が発生したらしい。例えば、大隕石が落ちてきて、多くの生命が失われ、わずかの生き残りから再び進化が進んで、高度な生物ができたと考えられている。
巡回セールスマン問題の場合に、最短距離の更新が長い世代に渡りなかった場合には進化が停滞してしまったと考えて、プール内のかなりの個体を作り直してしまう(天変地異を起こす)。こうすると、ときにはまた進化が進むことがある。
天変地異と書いたが、一般には焼きなまし法と言われている。
この方法についての実験は省略するが、ネットで検索するときには、焼きなまし法で探そう。
Raspberry Pi スパコンについて、延々と書いてきたが、次回は総括を行い最終回とする。

#人気の記事
#タグ


