CPUで一度に扱えるデータのビット幅は64ビットが限界と思っていないだろうか。
実は、いまどきのCPUは、64の8倍の512ビットのデータを一気に処理できる。元々はIntel系のCPUの拡張命令として始まり、最初はPenteium IIIが128ビットに対応し、その後ビット幅の拡張競争が続き、最近は512ビットに対応したAVX-512命令がサポートされているので、今回はそれを試してみようと思う。
基礎から説明を書くと長くなるので、専用の書籍が出ているので、それを紹介しておこう。

512ビット・ベクトルプログラミング入門
AVX-512 命令を駆使しよう
著者 :北山 洋幸
出版社 : カットシステム (2021/7/1)
発売日 : 2021/7/1
単行本 : 504ページ
ISBN-10 : 4877835075
ISBN-13 : 978-4877835071
定価 : 5000円+税
本書は、前半で並列演算を生かしたプログラム例を紹介し、後半は各命令の説明が延々と書かれたAVX-512命令のマニュアルとなっている。
円周率を求める
以下が、ライプニッツの円周率の公式である。

この公式の証明はネット上に多数転がっているので省略する。
さて、ここでは、C言語を使って、この無限級数をdoubleの長大な配列として用意し、その配列の総和を求めてみる。といっても、メモリに限界があるので、8バイトのdoubleが128M個(1.28億個)の配列、つまり全体で1GBのdoubleの配列の総和を求める。
まず、長大な配列を用意して、順に、 1,-⅓,⅕,-1/7,1/9,….を入れておく。
ふつうは、これを先頭から順に足していく訳だが、AVX命令では、ちょっと違う方法を行う。まず、AVX-512命令を扱うときには、__m512(float対応)または__m512d(double対応)という型を用意する。ここでは__m512dを用いて、doubleが8個連続した領域をsumとし、0.0に初期化する。

次に、長大な配列を512ビット単位でアクセスしていくため、ポインタは__m512d*で型指定する。すると、このポインタは++するたびに指し示すアドレスが512ビット(64バイト)ずつ進んでいく。
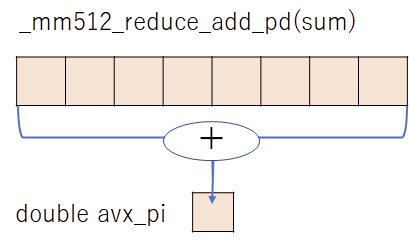
加算は、doubleを8回分を一気に加える。加え方は図のようになる。

これを級数の最後まで繰り返すと、sumに和が求まっているが、このままでは、8個おきに項を加算した和がsumに入っているので、総和を求めるには、sumの8つの値の和を求めて、普通のdoubleの変数に代入する。
プログラム
以上のことを愚直に書き、実行時間を計測し表示するようにした。
AVX-512命令と、C言語との実行時間比較も行った。
プログラム自体は単純なので、説明は省略する。
/*------------------------------------------------------------
長大な倍精度浮動小数点数の配列の総和
pi_avx512.c
gcc -O2 -mavx512f -o pi_avx512 pi_avx512.c
------------------------------------------------------------*/
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#include <immintrin.h>
int main(void){
clock_t start_clock;
const int arr_size = 1024*1024*128; // 約1.28億項までの配列
const int align_size = 64; // 512ビット
double* arr = (double*)_mm_malloc(sizeof(double)*arr_size, align_size);
for( int i=0; i<arr_size; ++i )
arr[i] = 1.0/(2*i+1) * ((i%2==0)?1:-1);
start_clock = clock();
const int units = sizeof(__m512d)/sizeof(double);
__m512d sum = _mm512_setzero_pd();
__m512d* parr = (__m512d*)arr;
for( size_t i=0; i<arr_size/units; ++i )
sum = _mm512_add_pd(sum,*parr++);
double avx_pi = _mm512_reduce_add_pd(sum);
avx_pi *= 4;
double t1 = (double)(clock()-start_clock)/CLOCKS_PER_SEC;
printf( "avx_pi=%.15f\t%f sec\n", avx_pi, t1);
start_clock = clock();
double c_pi = 0;
for( int i=0; i<arr_size; ++i )
c_pi += arr[i];
c_pi *= 4;
double t2 = (double)(clock()-start_clock)/CLOCKS_PER_SEC;
printf( " c_pi=%.15f\t%f sec\n", c_pi, t2);
printf( "速度比 = %f\n", t2/t1 );
return 0;
}コンパイルと実行結果
$ gcc -O2 -mavx512f -o pi_avx512 pi_avx512.c
$ ./pi_avx512
avx_pi=3.141592646141266 0.060916 sec
c_pi=3.141592646138478 0.139137 sec
速度比 = 2.284080doubleを8個を一度に加えているので8倍高速になるかというと、そういうことはない。
速度には、さまざまな影響がでてくるので、簡単には結論づけられないが、それでも倍以上の速度になる。
また、コンパイル時に最適化オプション -O2 としたが、これはCの最適化にはとても有効だが、AVX-512命令を使った場合、コンパイル時の最適化はほぼ無理だと思われる。
次に、最適化オプションなしでコンパイルし、実行した結果を示す。
$ gcc -mavx512f -o pi_avx512 pi_avx512.c
$ ./pi_avx512
avx_pi=3.141592646141266 0.078062 sec
c_pi=3.141592646138478 0.303132 sec
速度比 = 3.883221すると、速度比が4倍近くになった。AVX-512のときも少し遅くなったが、Cの場合は半分以下の速度になり、Cの最適化はかなり有効であることが分かる。
ここではとても簡単な例を示したが、科学技術計算を行う場合、2次元配列などで大量の数値データを扱うことが多い。そういう場合に、AVX-512 命令は真価を発揮する。
実際にプログラムをAVX-512化してみたい場合には、本書のサンプルプログラムは参考なろう。
C言語のプログラム例を示したが、本書にはアセンブリ言語版のプログラム例も色々載っている。

#人気の記事
#タグ


