前回の記事では RBS::Inline を導入する際にハマった話をまとめました。
この記事では、RBS::Inline の導入途中〜導入後の話をします。
型の優先度を変更した
RBS::Inline の導入が終わり、アプリケーションのすべての型の型コメントへの引っ越しを済ませた後に、型の更新スクリプトを見直しました。
これまでは、僕らの Rails アプリではいくつかの方法で型を管理していました。
- ソースコードから
rbs prototype rbコマンドで抽出したプロトタイプの型定義 - 手書きの型定義
- 各種型抽出 gem (rbs_rails, rbs_config, rbs_activesupport など)
これらの型に重複があった場合、「手書き > gem > prototype」という順位で型を採用していました。重複した型は rbs subtract コマンドを使って間引きを行っています。具体的な手順は RubyKaigi 2023 の pocke さんのトークのテクニック を参照してください。
これまでは
- prototype で生成した型は網羅性はあるが、型が指定されていない (untyped である)
- gem で生成した型は具体的な型を持っているが、網羅性は低い
- 手書きの型は具体的な型を持っているが、網羅性は低い
という性質を持っていました。
今回、RBS::Inline を導入したことで、この性質が以下のように変化しました。
- RBS::Inline で生成した型は網羅性があり、なおかつ(型コメントを書いた場所は) 具体的な型を持っている
- gem で生成した型は具体的な型を持っているが、網羅性は低い
そのため、RBS::Inline で抽出した型を最も信頼し、「RBS::Inline > ツール抽出」という順で重複した定義を間引くようにしました。このルール変更により、RBS::Inline が生成した .rbs ファイルをそのまま利用できるようになりました。
RBS::Inline の自動実行
これまでは型の生成には数分かかっていました。そのため、手元で型を再生成することはまったくなく、CI に型を生成させるという運用をしていました。しかし、RBS::Inline はファイル単位で実行をすると1秒以内に完了するため、オンデマンドに型定義ファイルを生成するのが現実的です。
先ほど述べたように、RBS::Inline が生成した型定義ファイルがそのまま利用できるようになったこともあり、ファイルの更新と連動して型定義ファイルが更新される環境を目指すことにします。
オンデマンドに RBS::Inline を実行する方法として、README では fswatch コマンドを使った方法が紹介されています。
$ fswatch -0 lib | xargs -0 -n1 bundle exec rbs-inline --outputしかし、このアプローチはソースコードを削除した場合、リネームした場合にはうまく動作しません。単にファイルの更新に合わせて rbs-inline コマンドを実行するだけでは、古いファイルが削除されずに残ってしまうため、型エラーが発生してしまうことがあります。
また、エディタを開くたびに fswatch コマンドを実行するのもひと手間です。ズボラな僕は fswatch を起動し忘れてファイルを書き換えてしまったことが何度かありました。
せっかく IDE を使っているのですから、こうした操作も意識せずに済ませたいですよね。ということで、自分が開発している VSCode 拡張の RBS helper に RBS::Inline の自動実行機能を追加しました。
- .rb ファイルの変更を検知して RBS::Inline を実行する
- .rb ファイルの削除を検知して、対応する .rbs ファイルを削除する
- .rb ファイルのリネームを検知して、対応する .rbs ファイルをリネームする
たったこれだけのシンプルな機能ですが、 rbs-inline コマンドをいっさい意識せずに型定義が更新できるようになりました。ソースコードを書き換えると RBS::Inline が型定義を更新し、連動して Steep が型チェックを行う、というサイクルが実現されています。
こちらが実行例です。左のソースコードを編集して保存すると、右の型定義ファイルが書き換わっているのがわかるでしょうか (vim モードなので保存のタイミングが分かりづらいかもしれません)。また、型が増えていくにつれ、型チェックのエラーが解消されていくのも見て取れますね。
RBS::Inline の実行は 1秒以内に完了するので、ほぼリアルタイムに型定義ファイルが更新されます。実際のプロジェクトでも、Steep LSP は開いているファイルの型チェックを優先的に実行してくれるのか、十数秒程度で型チェックの結果が届き始めるという感覚です。あまり速くはないものの、すごく待たされるわけではないという感じです。
なお、Steep はその後プロジェクトの全ファイルの再チェックを行うため、CPU はずっと回っていることになります。型に関係ない編集の場合は何も起きないので静かなものですが、メソッドの追加や型コメントの追加を繰り返していると、ずっと Steep が走り続けることになります。
VSCode で RBS::Inline の自動実行を行うには、RBS helper 拡張をインストールして、設定画面で機能を有効にします。RBS helper には RBS::Inline に関する設定項目が 4種類あります。
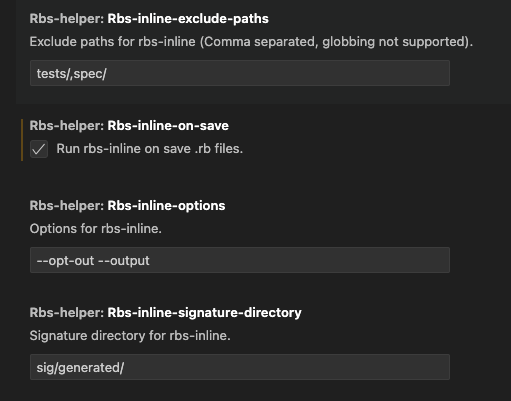
- Run rbs-inline on save .rb files
- .rb ファイルを保存するたびに RBS::Inline を実行するかどうか
- Signature directory for rbs-inline
- RBS::Inline で生成される .rbs ファイルの出力先ディレクトリ
- デフォルトは
sig/generated/
- Options for rbs-inline
- rbs-inline コマンドに渡すオプションを指定する (
--output以外) - デフォルトは
--opt-out
- rbs-inline コマンドに渡すオプションを指定する (
- Exclude paths for rbs-inline
- RBS::Inline の対象外としたいパスを指定する
- デフォルトは
tests/,spec/
まずは “Run rbs-inline on save .rb files” にチェックを入れて使ってみるとよいでしょう。
RBS::Inline の Lint
さて、ここまでのステップで RBS::Inline が自動実行できましたね。ソースコードを書き換えると型定義が更新される、幸せな型ライフを送ることができそうに思えます。しかし、まだ罠が潜んでいます。
現状の RBS::Inline は型コメントに間違いがあっても、エラーを発生させないので、ミスに気付けないという問題があります。
たとえば
-
#:コメントを書いていたつもりが#だった場合 - 引数名が間違っていた場合
- 型の文法エラー (カッコの不一致など)
などは単に無視されます。どうやら、 フォーマットに一致していないコメントは、単なるコメントと見なされてしまうのか、エラーなくサイレントに失敗してしまいます。
シームレスな環境ができたと思ったら、思わぬ落とし穴が待っているのです。
さて、Ruby でこういうときの解決法としてよく用いられるのは Rubocop ですよね。RBS::Inline 向けの Rubocop 拡張があるとすべてが解決しそうです。
ということで、 rubocop-rbs_inline を開発しました。この Rubocop 拡張は以下のような間違いを検知します。
- コメントの記述ミス (例:
#:が#になっている) - 型名の記述ミス (例:
Array[untyped]がArray[untypedになっている) - 存在しない引数名を指定している
その他、スタイルに関する指摘も行うようになっています。
この Rubocop 拡張を作ったことで、自分でもいくつかミスを検出して助けられています。
- into を info と typo していたり
- 不要なところに ? をつけていたり
- ブロック引数の変数名が間違っていたり
- インスタンス変数の定義が関数定義の中に混じっていたり
rubocop-rbs_inline を利用すると RBS::Inline 形式の型コメントを書く際に、ミスに気づきやすくなるはずです。
まとめ
RBS::Inline の導入中、導入後に考えた話をまとめました。
- 型の優先順位の変更 (subtract 順の変更)
- エコシステムの改善
- 自動実行の仕組みの追加 (VSCode拡張)
- Rubocop の Cop を作成
これらを整備することで、型の管理を意識外に置くことができ、メインコードと型コメントを意識するだけで、型が利用できる世界に一歩近づきました。
まだ課題は多いですが、型のある世界に徐々に近づいていますね。

#人気の記事
#タグ


