学習の進行状況を把握するにはグラフがなんと言ってもわかりやすい。
仕方がないから、ちょっとプログラムして、グラフを作るしかないかな。
と思ったら、resultというフォルダができていて、その中に何やら色々なものができていた。
その中に、accuracy.png と loss.png があり、こんな感じになっていた。
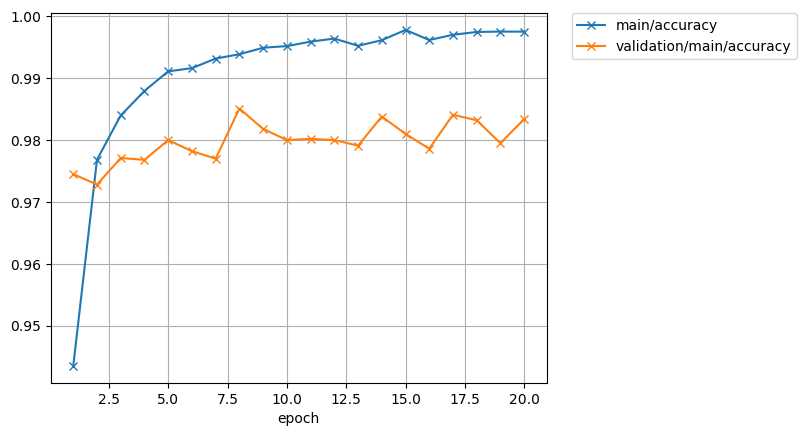 青線が学習精度曲線であり、オレンジ線がテスト精度曲線である。
青線が学習精度曲線であり、オレンジ線がテスト精度曲線である。
学習曲線は、1.00にかなり近いところまでいっている。
テスト曲線(検証曲線)との差はグラフからはかなりあるように見えるが、0.015(1.5%)程度である。
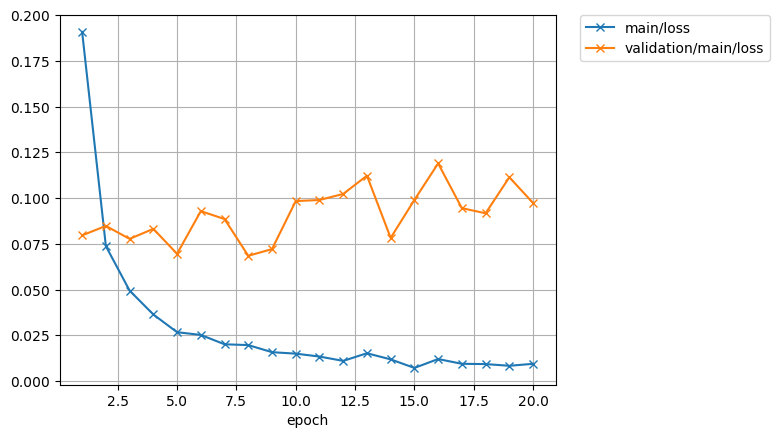
もう1つのグラフがロス関数(誤差関数)というものであり、上の図をちょうど上下反転したような形になっている。
さて、データ数が少なくなったら学習曲線がどんな風に変わったか、n=500の場合の精度の変化の様子を見てみよう。
仕方がないから、ちょっとプログラムして、グラフを作るしかないかな。
と思ったら、resultというフォルダができていて、その中に何やら色々なものができていた。
その中に、accuracy.png と loss.png があり、こんな感じになっていた。
accuracy.png -n 60000
青線が学習精度曲線であり、オレンジ線がテスト精度曲線である。学習曲線は、1.00にかなり近いところまでいっている。
テスト曲線(検証曲線)との差はグラフからはかなりあるように見えるが、0.015(1.5%)程度である。
もう1つのグラフがロス関数(誤差関数)というものであり、上の図をちょうど上下反転したような形になっている。
loss.png -n 60000
さて、データ数が少なくなったら学習曲線がどんな風に変わったか、n=500の場合の精度の変化の様子を見てみよう。
accuracy.png -n 500
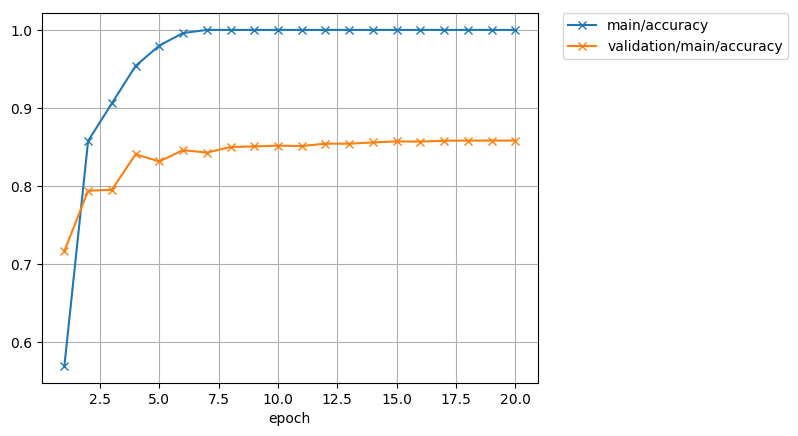 今度は、学習精度が早い段階で1.00になってしまっている。
今度は、学習精度が早い段階で1.00になってしまっている。
これだけ見ると、非常に学習が順調に進んだように見える。
しかし、テスト精度の方は、0.85あたりでふらふらしているので、学習とテストでは精度が0.15(15%)も違い、エポックが進んでも差は縮まらないようだ。
学習データが60000個の時の10倍もの誤差になってしまった。
こういう風に、学習精度だけ上がって、テスト精度との差が縮まらない状態を過学習という。
つまり、学習のデータを学習し過ぎて、学習データは完璧に判定できるようになったものの、本番データを入れたら精度が悪いということである。
これを避けるためには、大量のデータを使って学習しないとダメということだ。
それにしても、こんなグラフまで何もしないで作ってくれるchainerのサンプルプログラムは素晴らしい。
今度は、学習精度が早い段階で1.00になってしまっている。これだけ見ると、非常に学習が順調に進んだように見える。
しかし、テスト精度の方は、0.85あたりでふらふらしているので、学習とテストでは精度が0.15(15%)も違い、エポックが進んでも差は縮まらないようだ。
学習データが60000個の時の10倍もの誤差になってしまった。
こういう風に、学習精度だけ上がって、テスト精度との差が縮まらない状態を過学習という。
つまり、学習のデータを学習し過ぎて、学習データは完璧に判定できるようになったものの、本番データを入れたら精度が悪いということである。
これを避けるためには、大量のデータを使って学習しないとダメということだ。
それにしても、こんなグラフまで何もしないで作ってくれるchainerのサンプルプログラムは素晴らしい。

#人気の記事
#タグ


