データ解析のための統計モデリング入門 GLMの応用範囲をひろげる 読書メモ4
2017年 04月 18日
このブログ記事は『データ解析のための統計モデリング入門』(久保拓弥 著、岩波書店)という、とても分かりやすい統計モデリングの入門書を、さらに分かりやすくするために読書メモをまとめたものです。
今回は第6章、GLMの応用範囲をひろげるについてのまとめの四回目です。
この章では様々なタイプのGLMについて説明がされています。
まずはロジスティック回帰について説明されています。
なので、サンプルデータを用意して、ロジスティック回帰をやってみるコードを用意しました。
コードはRで書きました。
N <- 100
dataSize <- 100
createData <- function(createY) {
createY <- match.fun(createY)
x <- runif(dataSize, 0, 200)
y <- createY(x)
data.frame(x, y)
}
dataGenerator <- function()
createData(function(x) rbinom(dataSize, N, 1 / (1 + exp(5.0 - 0.05 * x))))
data <- dataGenerator()
fit <- glm(cbind(y, N - y) ~ x, data = data, family = binomial)
b1 <- fit$coefficients[1]
b2 <- fit$coefficients[2]
linkFunction <- function(x) 1 / (1 + exp(-b1 - b2 * x))
xs <- 1:200
ys <- 0:N
title <- "Logistic regression"
xl <- "x"
yl <- "The most probable y"
maxY <- numeric(length = 200)
for (x in xs) {
q <- linkFunction(x)
maxY[x] <- which.max(dbinom(ys, N, q)) - 1
}
plot(0, 0, type = "n", xlim = c(0, 200), ylim = c(0, N), main = title, xlab = xl, ylab = yl)
lines(xs, maxY, type="l")前回もサンプルデータに対してロジスティック回帰をやってみて結果をプロットしました。
今回は説明変数 x に対して、どの応答変数 y が一番高い確率で得られるかをプロットしました。
コードを実行すると下図のような図がプロットされます。
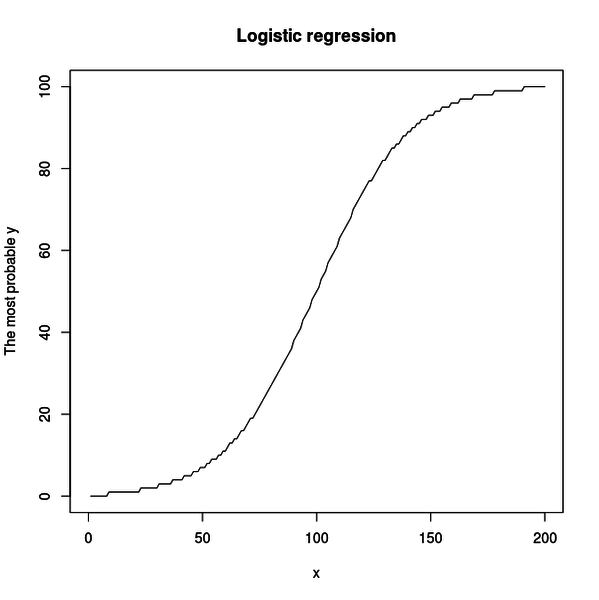
ロジスティック関数のような曲線が得られました。
もちろん y の値はこの曲線の周囲に分布しているわけですが、一番取りやすい値をつなげると、このような曲線になるということです。

#人気の記事
#タグ


